
|
|
| HOME |  |
ソリューション | |
|
受託開発 | |
会社情報 | |
採用情報 |
| GA 事例紹介 |
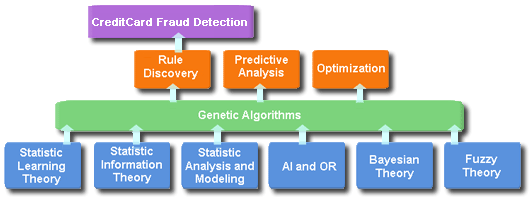
| クレジットカード 不正使用の検知 |
| 潜在離反顧客の早期発見 |
| 初期・途上与信のためのスコアリング |
| 顧客ライフタイム バリューのマイニング |
| 人員配置 スケジューリング |
| 物流システムの最適化 |
| 地図ラベルの自動配置 |
| 広告の最適化 |
| DM応答率最大化 |
| 商品の レコメンデーション |
| 潜在休眠顧客の予想と 休眠顧客の活性化 |
| 石油精製の最適化 |
| FX自動ヘッジモデル |
| プライバシーポリシー | サイトマップ | ビバサイエンス | メディカルシグマ | Copyright(C) 2011 JANA Solutions, Inc. All Rights Reserved |